70亿参数规模大模型新选择:Deci开源DeciLM-7B大模型,评测效果远超Llama2-7B,每秒可生成328个tokens。
DeciAI是一家成立于2019年的以色列企业,他们最主要的产品是深度学习平台Deci,可以让大家部署运行更快、更准确的模型。包括Adobe、HPE等都是他们的客户。在昨天,他们开源了截止目前可能是Open LLM Leader综合评分最高的大语言模型DeciLM-7B以及指令优化版本的DeciLM-7B-Instruct。最重要的是,这个模型以Apache2.0的协议开源,可以免费商用。
DeciLM-7B简介
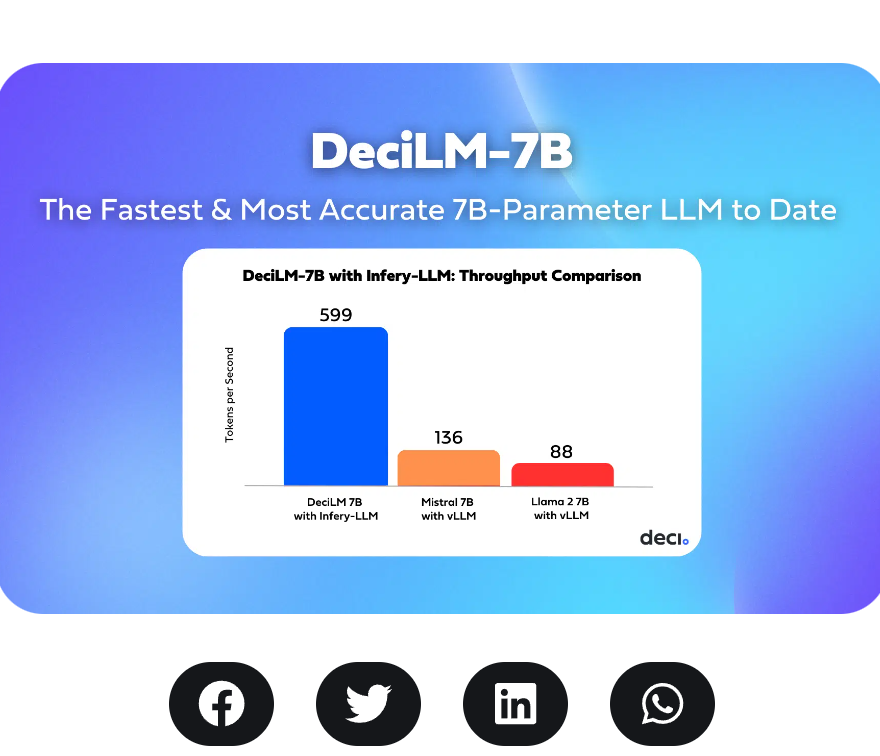
DeciLM-7B模型是一个参数规模为70.4亿的大语言模型。它是DeciAI自己从头训练的大语言模型。其模型架构虽然没有完全公开,但是从官网提供的信息看是一个非常具有创新性的transformer架构,是一个速度与效果均衡的大语言模型,作为一个预训练模型,它在各项评测得分中都有很好的结果,综合成绩目前是70亿参数预训练模型中Open LLM Leader排行榜第一。
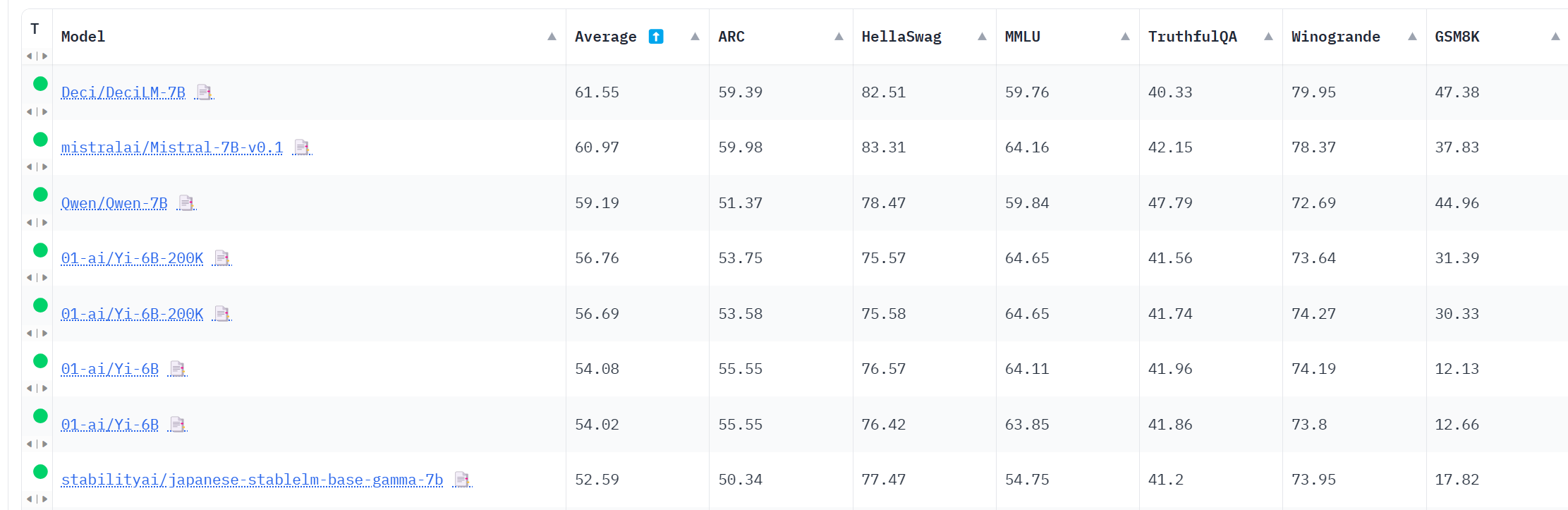
Open LLM Leader是HuggingFace4H在HuggingFace上创建的一个排行榜,用以跟踪大模型在各个评测上的得分结果。其中,模型可以按类别和参数规模分组。这个榜单的访问量很高,也是很多人关注的一个榜单。它可以自动地评估模型在不同评测任务上的得分结果。而目前,70亿参数预训练模型的综合的份上,DeciLM-7B第一,略超第二名的Mistral 7B模型。
DeciLM-7B是一个基础语言模型,同时发布的还有一个指令调优的语言模型DeciLM-7B Instruct,而这两个模型的预训练结果都是以Apache 2.0协议开源的,所以可以完全免费商用。
DeciLM-7B模型的技术细节
尽管官方没有公布DeciLM-7B的详细信息,但是还是公布了一些技术小细节。首先,DeciLM-7B采用了DeciAI自家的神经网络架构搜索引擎创造,同时采用了一种新的Grouped Query Attention技术。可以结合Multi-Query Attention的速度和Grouped Query Attention的效果。简单来说就是部分层使用MQA,部分层使用GQA。但是没有公布更多细节。

