OpenAI发布最新Embedding模型——可惜又是一个收费API
嵌入(Embedding)是深度学习方法处理自然语言文本最重要的方式之一。它将人类的自然语言和文本转换成一个浮点型的向量。向量之间的距离代表了它们的关系。今天,OpenAI宣布了他们的Embedding新模型——text-embedding-ada-002。官方宣称这是目前OpenAI最强的嵌入模型,可以将任意文本转换成一个向量,且效果好于目前所有OpenAI的模型。
嵌入是一种相对低维的空间。借助嵌入,可以更轻松地对表示字词的稀疏向量等大型输入进行机器学习。理想情况下,嵌入会将语义上相似的输入置于嵌入空间中彼此靠近的位置,以捕获输入的一些语义。嵌套可以跨模型学习和重复使用。Embedding可以在如下领域发挥作用:
- 搜索(根据查询字符串的相关性对结果进行排名)
- 聚类(根据相似性对文本字符串进行分组)
- 推荐(具有相关文本字符串的项目被推荐)
- 异常检测(识别关联度小的异常值)
- 多样性测量(对相似性分布进行分析)
- 分类(文本串按其最相似的标签进行分类)
今天发布的text-embedding-ada-002模型有如下特点:
强大的性能
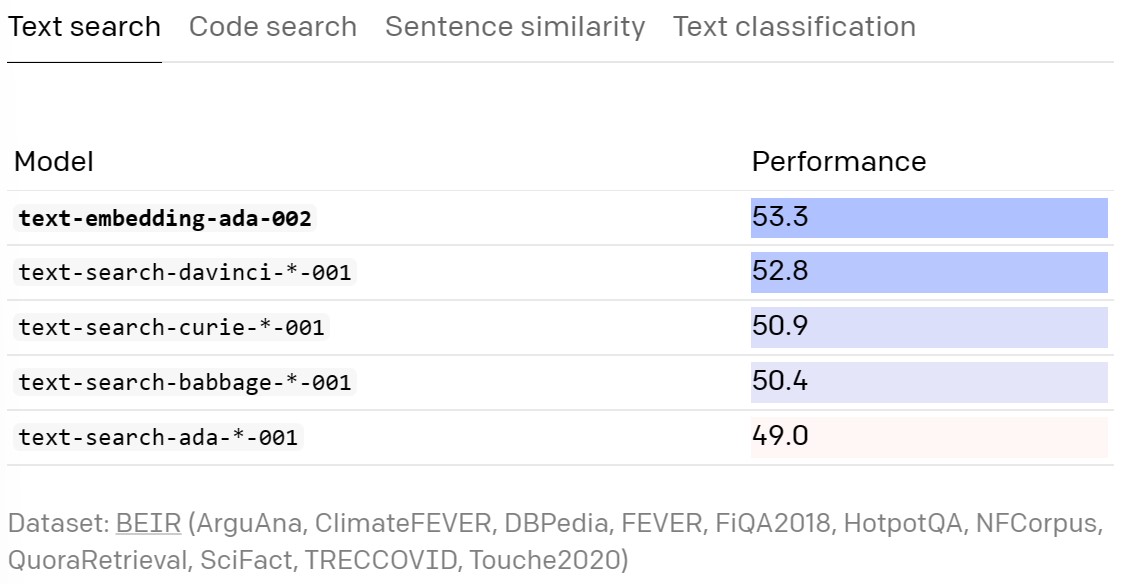
text-embedding-ada-002在文本搜索、代码搜索和句子相似性任务上优于所有旧的嵌入模型,并在文本分类上获得相当好的性能。
下图就是文本检索领域的评测结果:
统一能力
OpenAI通过将上述五个独立的模型(文本相似性、文本搜索-查询、文本搜索-文档、代码搜索-文本和代码搜索-代码)合并为一个新的模型,大大简化了/embeddings端点的界面。在一系列不同的文本搜索、句子相似性和代码搜索基准中,这个单一的表述比以前的嵌入模型表现得更好。
更长的上下文
新模型的上下文长度增加了4倍,从2048到8192,使得它在处理长文档时更加方便。
更小的嵌入尺寸
新的嵌入只有1536个维度,是davinci-001嵌入尺寸的八分之一,使新的嵌入在处理矢量数据库时更具成本效益。
降低了价格
与同样大小的旧模型相比,新嵌入模型的价格降低了90%。新模型以99.8%的价格实现了与旧Davinci模型更好或类似的性能。
虽然性能看起来不错,但是似乎贵了点,更重要的是国内用不了。
